
Preserving sites for the long haul


Preserving websites and web content for the long haul is important to our team! CMS's get updated, plugins go out of date, and PHP versions change, which means that your dynamic sites often need tending to over time. An essential aspect of preservation is thinking about how to flatten, or archive dynamic sites that are no longer going to be updated, to make sure they continue to be accessible!
There are several tools out there that can flatten sites to HTML files that are worth checking out, like SiteSucker on macOS, and HTTrack on Windows and Linux. It is also worth checking out the family Webrecorder tools, including ArchiveWeb.page and ReplayWeb.page. All these tools are fantastic, but each has their strengths and weaknesses. Flattening tools like SiteSucker and HTTrack don't work with every type of site, and Webrecorder's tools work with almost any site, but can be difficult to learn how to archive an entire site and all its pages. This is why we made the Site Archiving Toolkit!
The Site Archiving Toolkit allows you to quickly and easily make both flattened HTML and web archive versions of websites. It provides a relatively easy to use command line interface for crawling sites using both HTTrack and Browsertrix Crawler (from the Webrecorder project). These archives can be stored on Reclaim Cloud and linked to, but are also zipped and easy to download, where they can be placed on any web server for others to view!
Using the Site Archiving Toolkit
You can try out the Site Archiving Toolkit on Reclaim Cloud by installing it from the Marketplace.
Once it's installed, use the Web SSH button to open the terminal:
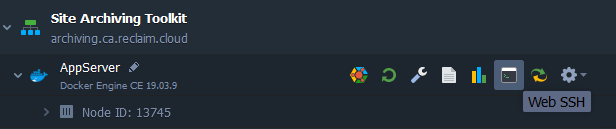
Finally, use the archive command to start crawling a site! Type archive and give it a URL (starting with http:// or https://) to crawl. You can even give it multiple URLs at once, separated by spaces.
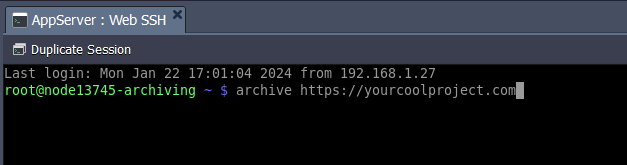
While the crawl runs, you can watch its progress, or close the terminal. You do not need to keep the tab open in your browser for the toolkit to keep running.
You can visit the environment's URL to see all in progress crawls, check logs, view past crawls, and download them!
The page will show all past crawls sorted by time. Any currently running crawls will be marked "INCOMPLETE".
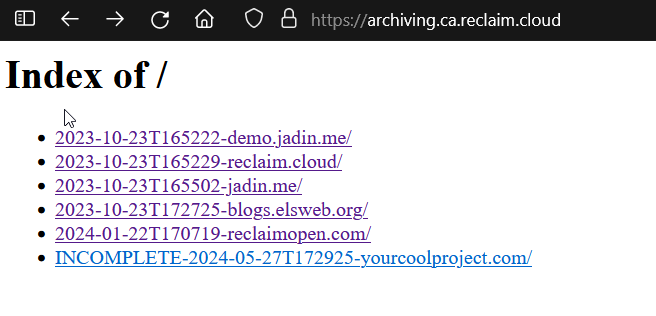
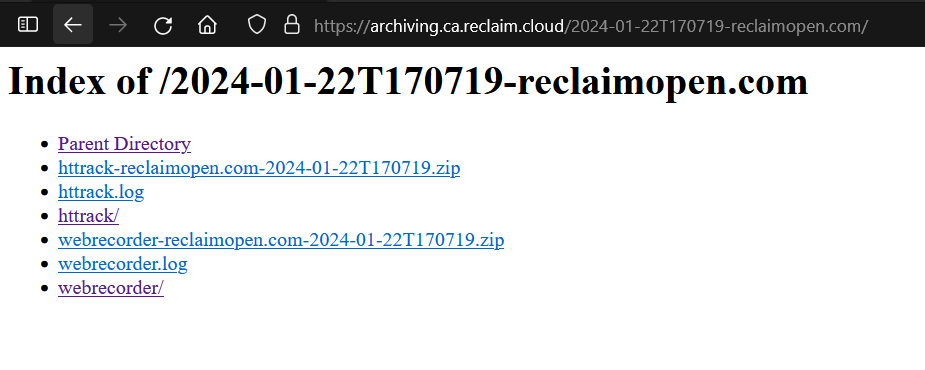
Clicking on a particular crawl allows you to view both the httrack and webrecorder versions of the site, by clicking on those respective links. You can also see the logs for each by clicking on the .log files, or download each archive to your computer by clicking on either of the .zip files.
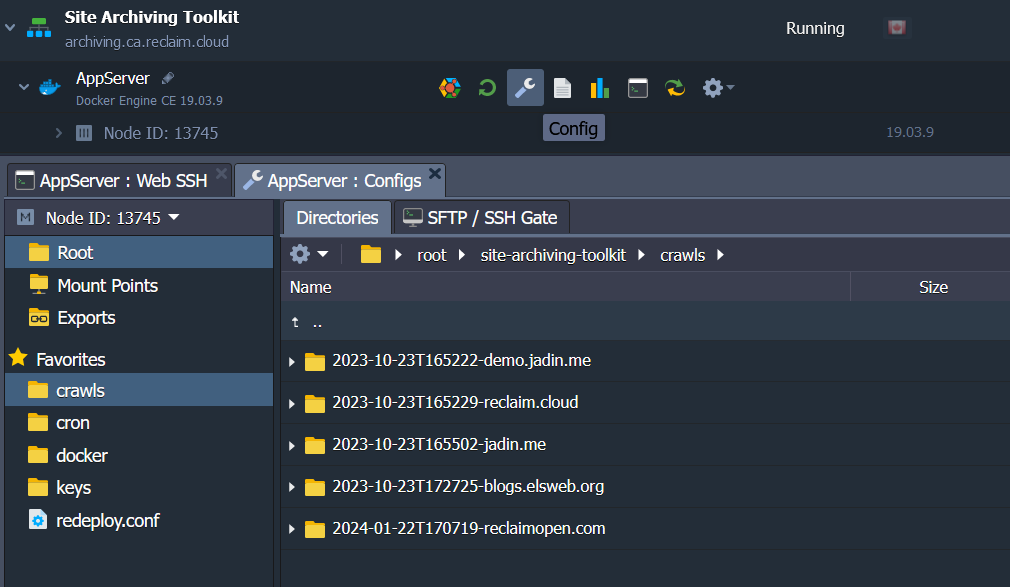
Finally, you can use the Config button, then click on crawls in the left sidebar to rename each crawl or delete crawls you no longer need.
We've got further information on the Site Archiving Toolkit itself, and how to use some of its more advanced features on GitHub:
TaylorJadin/site-archiving-toolkit - GitHub
We also did a Reclaim TV stream on the Toolkit shortly after it was released:
Archiving and Flattening Projects
We are happy to work with you if you have a flattening or archival project that you need help with, large or small. Last year, we helped archival and preservation of the UMW Blogs platform, as UMW started its new multisite Sites@UMW. You can check out the UMW Blogs archive by visiting its original domain, umwblogs.org!
You can also check out the Reclaim TV stream that we did about the archival work:



